今天是 2023 年 3 月 15 日,您看到的是第 159 期 AI Insider。
本期 AI Insider 是大语言模型特辑,从刚刚发布的 GPT-4 的三个变化谈起,探讨大模型领域闭源与开源的关系,以及开源大模型正在产生的影响,最后关注大模型的企业应用与疯狂的 AI 创投市场。
接下来,欢迎和我一起复盘围绕计算与智能的产业动态。
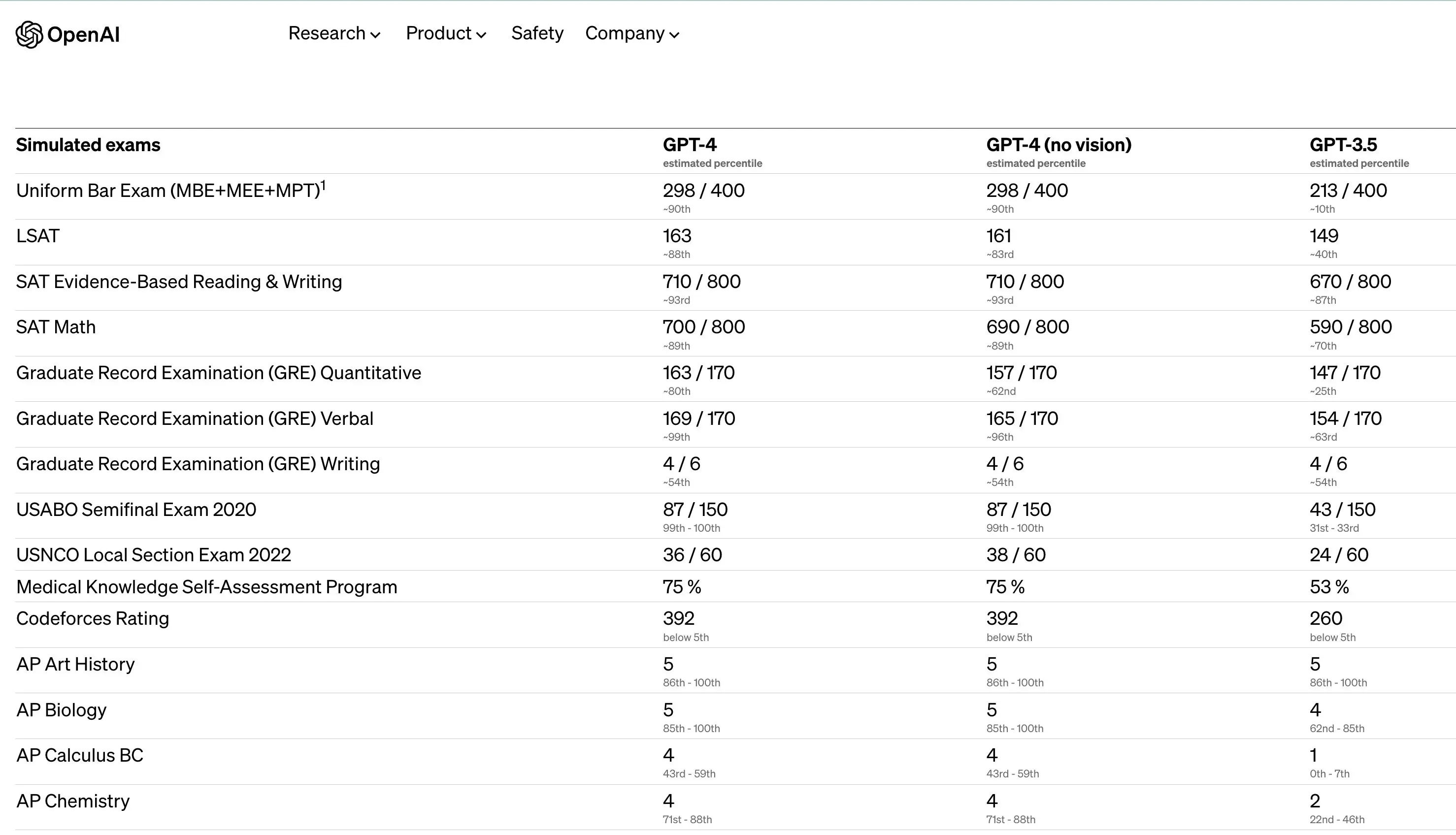
尽管此前已经有多个爆料,但 GPT-4 正式发布的消息还是引发诸多讨论,结合 OpenAI 给出的新闻稿来看,此次更新不再过度强调参数规模,而是重点展示其能力,既包括对图像输入的支持(暂未开放 API),也包括应对众多人类社会的能力测试,比如接近满分的 GRE、700 分的 SAT 成绩单等。
更进一步,GPT-4 的逻辑推理能力继续增长,在律师模拟考试里,GPT-4 能够进入到前 10%,而基于 GPT-3.5 的 ChatGPT 大概只能排在倒数 10% 的名次。
这份成绩单也让英伟达 AI 科学家 Jim Fan 感叹:GPT-4 完全可以向斯坦福大学提交入学申请。
不过,这种基准测试到底意味着什么还存在一定争议,NYT 计算机教授 Gary Marcus 指出,「benchmarks ≠ robust intelligence」,原因在于,GPT-4 的做题方式和人类测试的方式完全不同,由此宣传很容易给公众产生误导。
其次,GPT-4 谈论了很多大模型落地的案例与方法。比如鼓励开发者或企业快速调取 GPT-4 的 API,虽然目前还有额度限制,但已经展示出不俗的进步。
再比如,GPT-4 的新闻稿网页集中介绍了多家公司或政府的实践案例,包括语言学习应用 Duolingo、金融服务 Stripe、金融巨额摩根斯坦利以及爱尔兰政府等,这进一步凸显出大语言模型的巨大应用前景,也是 OpenAI 商业化运营的阶段性成果。
特别提醒的是,微软新 Bing 已经更新到 GPT-4。
第三,GPT-4 也在提升对「越狱」的屏蔽能力,官方给出的数字是:根据内部测试,对不合规内容的响应请求减少了 82%,响应准确度增加了 40%。这个数字更多还是为了市场宣传,实际应用中能有多少变化,还需要在后续测试中继续观察。
对于 OpenAI 来说,保持 GPT 系列大模型闭源是其商业模式,但有闭源就一定有开源。上月,Meta 向研究者开放了多个大语言模型 LLaMA(参数规模从 70 亿到 650 亿),这个模型很快就被泄漏,换句话说,它成了一个「被开放」的大语言模型,由此也掀起了一系列优化大模型的潮流:
我们有理由相信,基于开源社区的机制,这一系列面向大模型优化的趋势不会停止,我们也有理由相信,运行大模型的硬件条件会越来越低,从只能使用英伟达昂贵的 A100 GPU 到仅需 CPU,如此快速的变化会让大模型领域的未来更具戏剧性:
而随着大模型硬件需求的持续下降,对处在高端芯片限售危机中的中国公司来说是一大利好。
关注大语言模型在企业市场的两个应用场景:
值得一提的是,微软将在美西时间本周四举行一场关于 AI 与未来办公的主题活动,微软 Office 套件如何与 OpenAI 相结合会成为一大看点。
ChatGPT 持续推动 AI 创投市场的火热,一家仅有四个前 Google 工程师的 Mobius 公司,在没有任何产品甚至规划的情况下,一周内得到 a16z、Index 的投资,估值超过 1 亿美元,还被其他风险投资公司「围追堵截」。
NYT 梳理了近期获得融资的公司:
上述这些公司几乎没有产品,更谈不上商业模式,风险投资所看重的,既包括创业者的资历和经历(来自 Google、OpenAI 的工程师最受欢迎),也包括对所谓「赛道」的判断,特别是在元宇宙、加密货币等「赛道」衰退的行业背景下,资本需要新的流向,从而创造新的增长点。
不过对于资本以及一众创业公司而言,至少还需要克服两大难题:
这或许也可以解释某些风险投资公司的立场:与其投资 AI 创业公司,不如去购买那些押注 AI 的科技巨头们的股票。
这封邮件是 Dailyio Pro 及 Premium 的专属内容,但我欢迎您将这封邮件转发给您身边关注或从事 AI 与云计算的朋友。