✍️ 信息创造
探索基于大语言模型的内容创作流程。八个月前的 12 月 6 日,我在尝试了一周 ChatGPT 之后分享了其对内容创作者(特别是文字内容创作者)的价值,我在当时的会员通讯里写道:
在过去十几年里,键盘与输入法解决了我快速写下来的难题,各类优秀的笔记工具帮我攻克高效写下去的困境,从现在开始,以 GPT-3 为代表的各类语言大模型,可能会给我——以及更多爱好写东西人——带来一次范式革新:
- 人类负责思考,写出关键词;
- 语言大模型负责呈现这些思考,输出文本;
- 人类校对这些输出的文本(或者,让另一个模型校对?);
过去半年多的时间里,各类大语言模型持续进化,而包括我在内的内容创作者也在探索基于这些模型的内容创造流程,从思考助理到写作助理,从通用大模型到个人专属模型,大语言模型已经成为我的内容生产流程的「关键先生(或女士)」。
比如,大模型可以快速处理新闻线索,以确定这些线索之间有哪些潜在的或者我无法意识到的关系。此前我需要利用思维导图或 Workflowy 之类的大纲工具进行整理和思考,现在我的工作流程是:
- 将新闻线索整理成简洁表达的文本;
- 将这些文本交给 ChatGPT 之类的大模型;
- 使用「分析这些线索之间的关系」之类的提示词;
- 结合输出的结果,再输入一些背景资料,进一步优化这些关系;
下图展示的是与 Claude+ 模型互动:

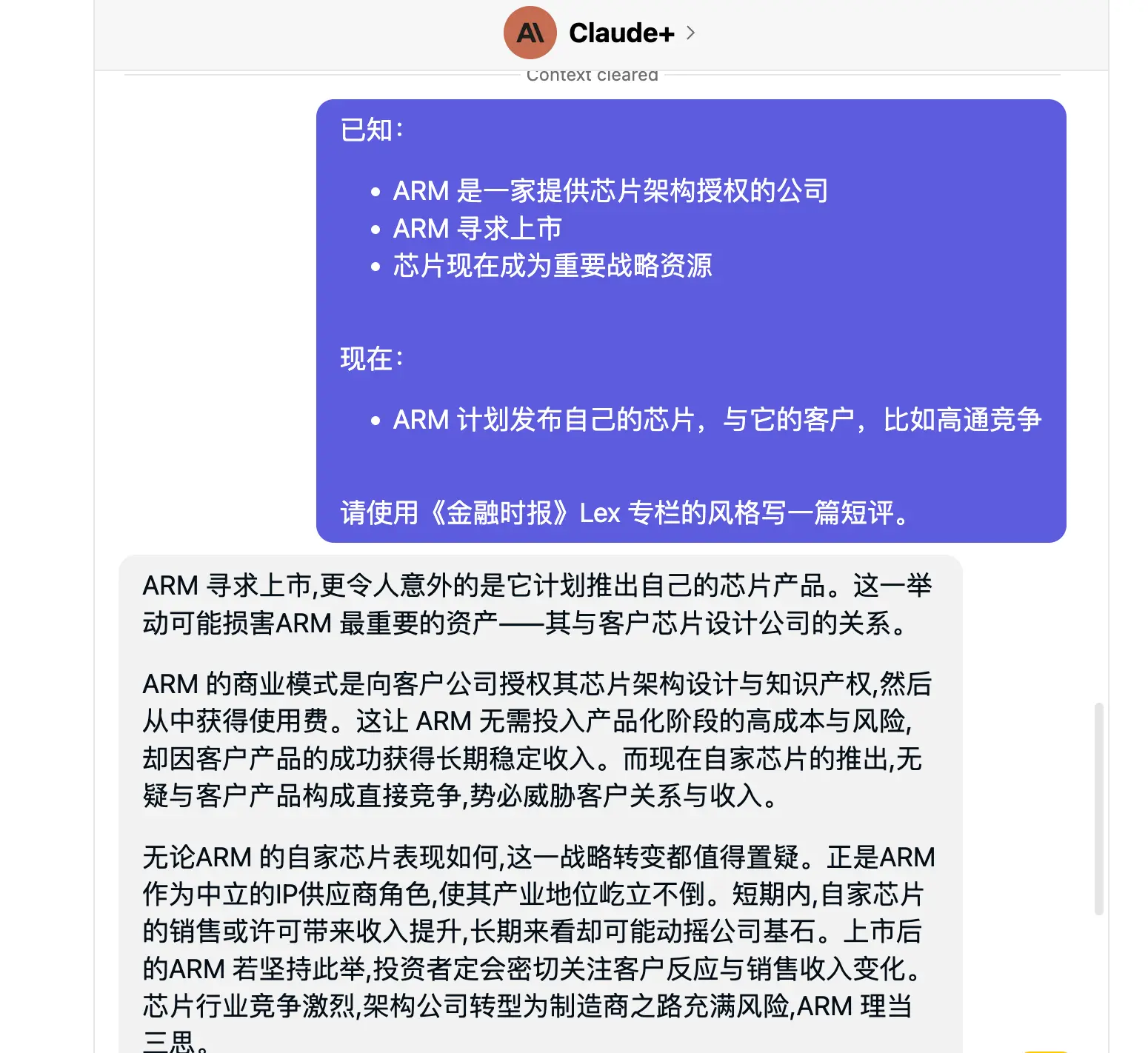
再比如撰写某一类风格的内容,我个人很喜欢读《金融时报》的 Lex 评论专栏,这个专栏篇幅短小精悍,观点鲜明,有时候我希望让大模型帮助我模仿 Lex 专栏的风格,评论一些产业动态,整个流程包括:
- 将一篇 Lex 专栏文章复制粘贴,发送给大模型(比如 Cladude+ 或 GPT-4),让大模型了解它接下来需要模仿的文章风格是什么;
- 整理要撰写评论的素材,包括事件简要描述、相关数据以及希望生成的观点类型(积极或消极);
- 根据大模型的输出,重新调整或修订;
下图是一个示例:
第三,使用自己的专属模型,让大模型分析我曾经创作的内容,提供内容创作的新灵感。比如利用微软 Edge 浏览器与 Bing 的组合,首先使用 Edge 浏览器直接读取一份过往邮件通讯的文本存档,然后借助 Bing 结合文档内容,创作新的内容:
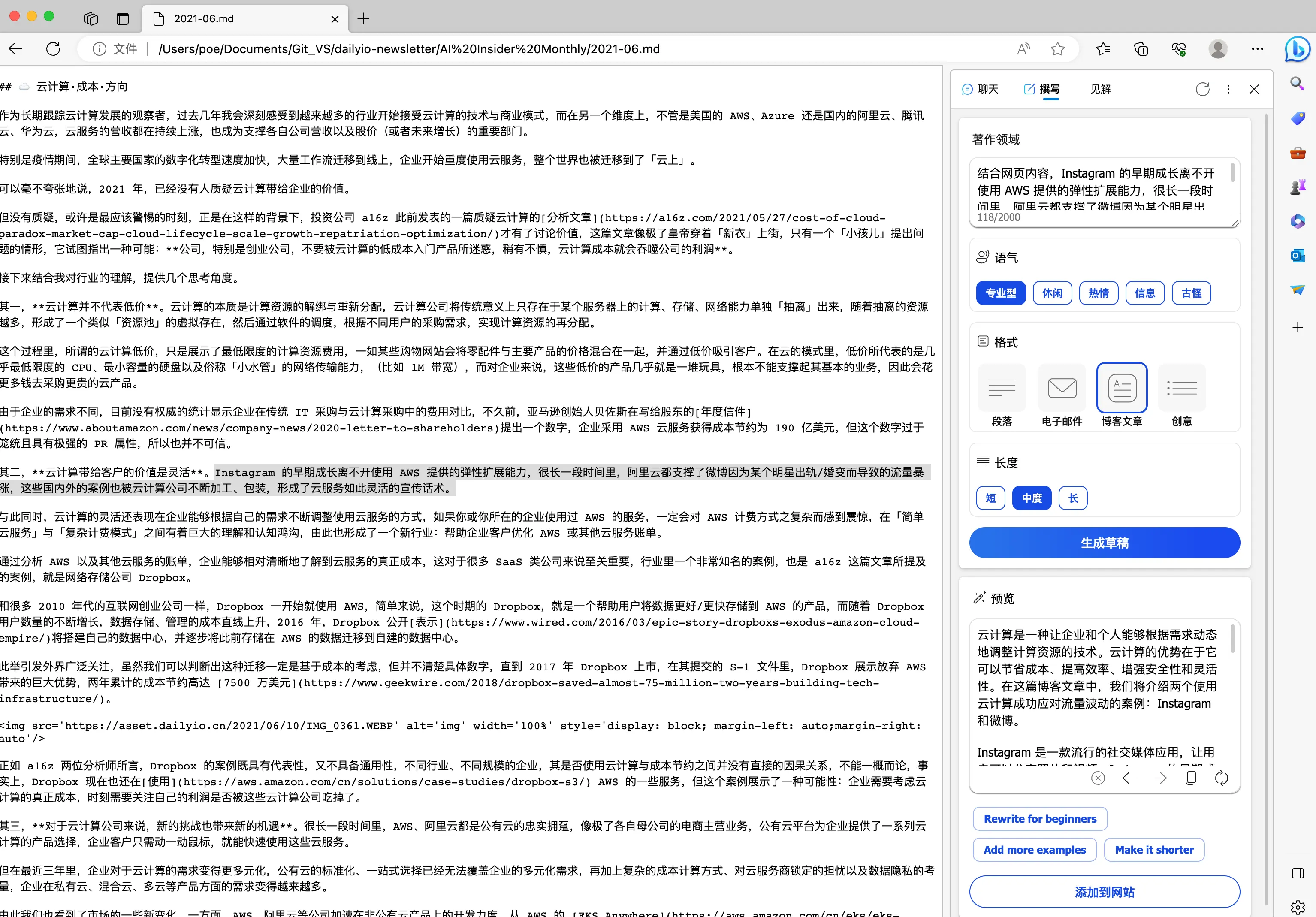
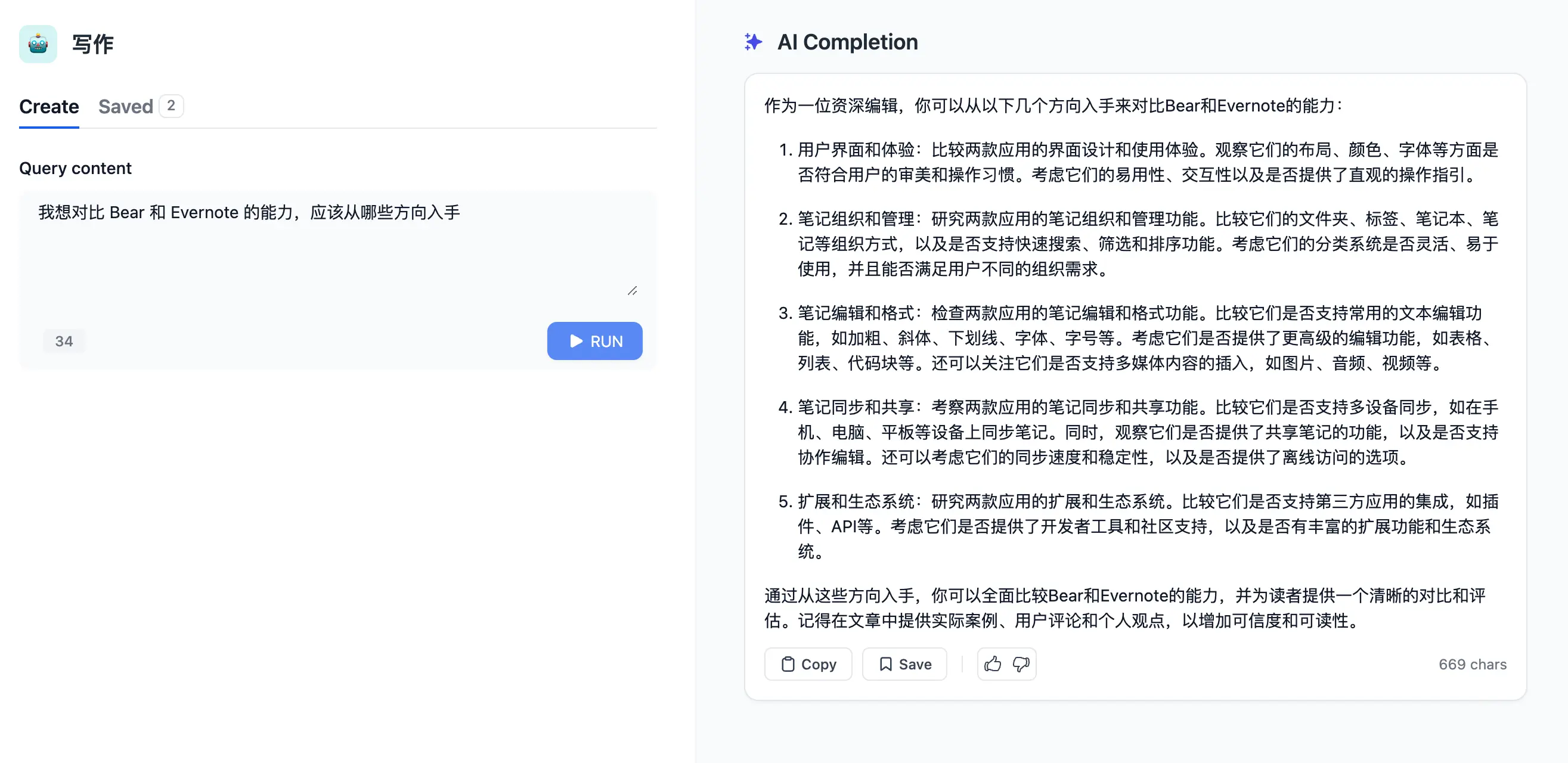
Edge 浏览器每次只能处理一个文档,而且无法「记住」过往的文档内容,于是,我使用 Dify 构建了一个专属写作灵感应用,首先把过往所有创作内容变成「数据集」,然后使用 OpenAI API 进行对话:
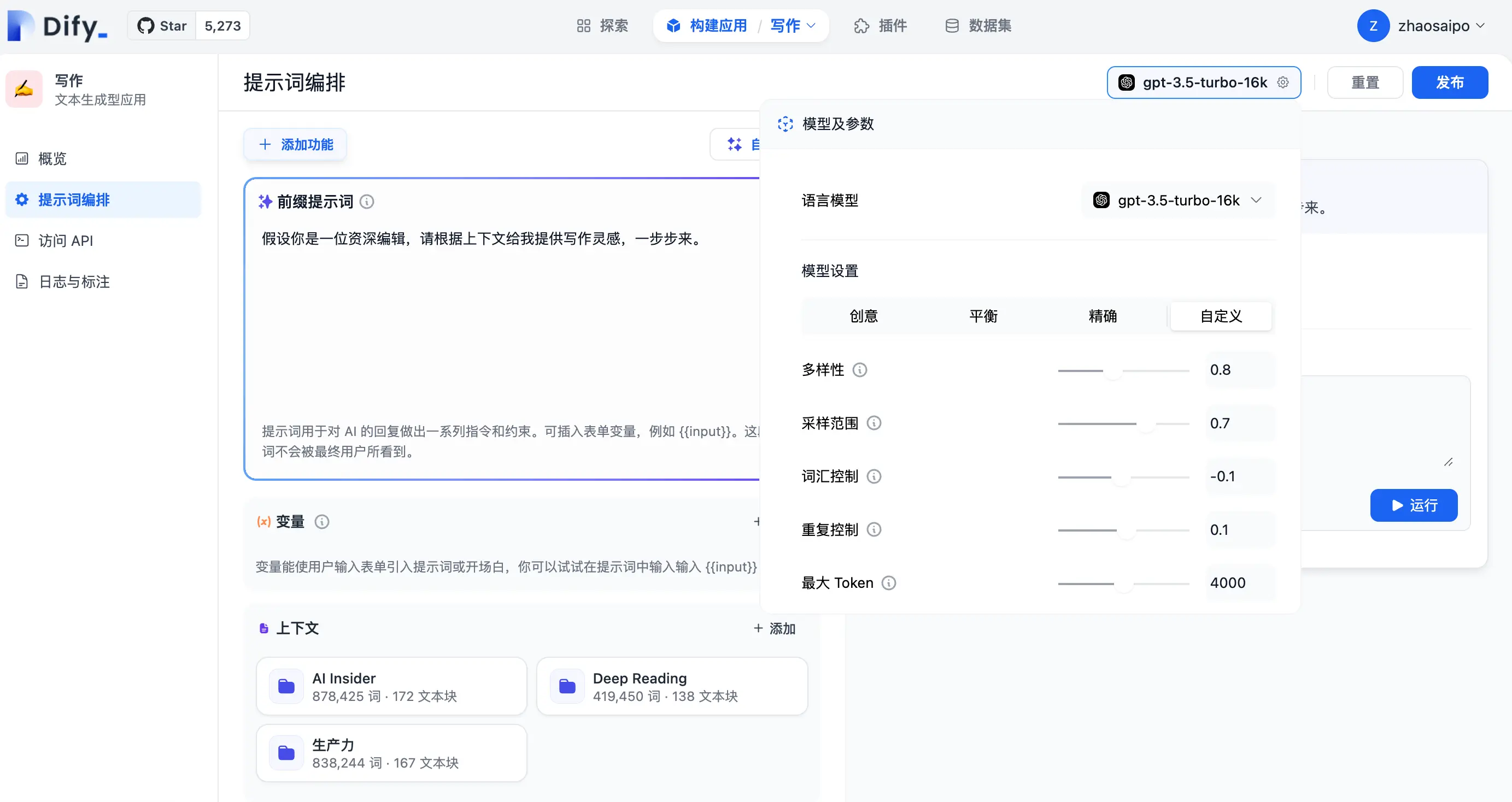
Dify 有趣的地方在于,你可以灵活调整模型对于内容的处理方式,包括系统提示词的设置、模型选择以及调参等,如下图所示,能够让这个应用的输出不断优化,更符合我的需求:
当然,上述三个方面仅仅是我个人基于自身习惯构建的流程,如果你还有新颖的使用流程,欢迎回复这封邮件与更多朋友分享。另一方面,我也相信随着大模型能力的持续发展以及调用模型的价格、技术门槛持续下降,未来我们会有更多使用大模型优化内容创作的方式与方法。
|