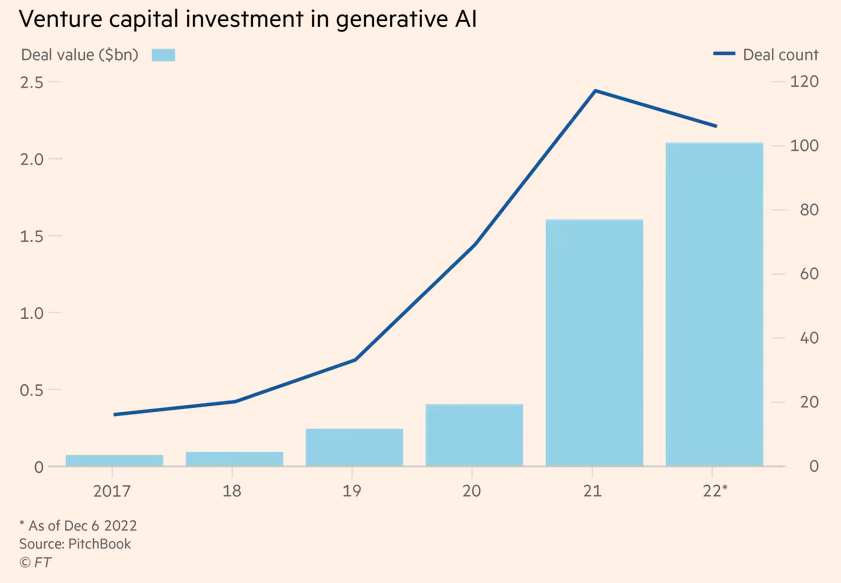
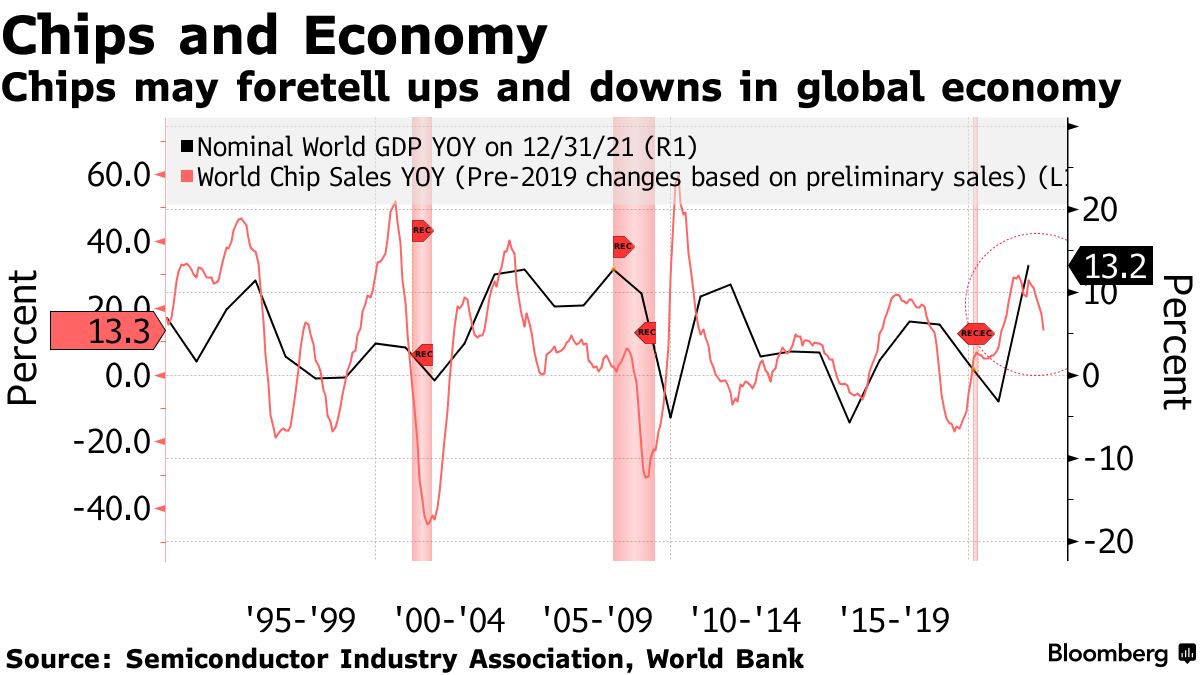
趋势 3:AI 大模型持续进化,成为科技巨头的新护城河
超大规模语言模型的快速发展,不仅直接推动了生成 AI 应用的落地,还在酝酿新的产业机会。
新一年,超大语言模型的迭代当然不会停止,被认为 GPT-3.5 的 ChatGPT 已经足够令行业震惊,即将发布的 GPT-4 会带来惊喜还是惊吓,会成为 2023 年最值得期待的事件。
其次,即便是已经发布的大模型,其潜力到底有多大依然存在未知,比如 DeepMind 基于 Google 通用语言模型 PaLM 构建了「Med-PaLM」大模型,能够应对一系列医疗问答场景的问题;再比如,是否存在一些能力(或者说功能)只出现在大模型而不会出现在小模型里?如果存在,如何理解「大模型的涌现能力」?这些关于大模型潜能的研究也会贯穿 2023 年。
第三,科技巨头们会将大模型变成自身技术与产品的护城河。微软 2019 年对于 OpenAI 的投资正在成为史上最成功的 AI 投资之一,基于 OpenAI 不断推出的大模型,微软持续为诸如 Github、Office、Azure 等产品线注入新特性,大模型俨然成为微软的核心能力。
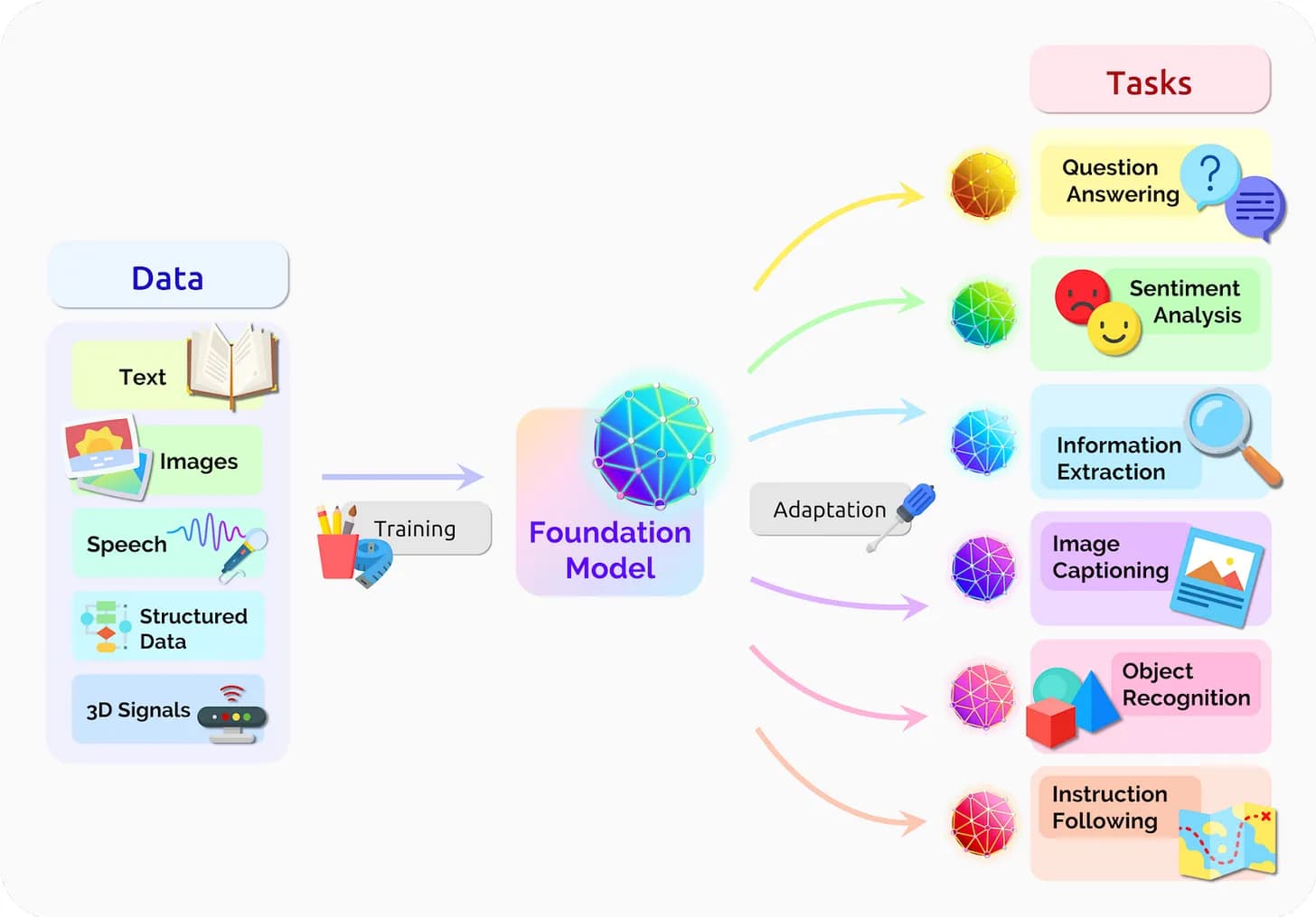
2023 年,无论微软是否会以 100 亿美元入股 OpenAI,其他中美科技巨头们——Google、亚马逊、苹果、阿里巴巴、百度——都会持续发力这个领域。特别是对众多云计算公司而言,接下来的一年,我们会看到一系列基于云服务的大模型产品,面向企业市场,开箱即用。
不过遗憾的是,在诸如 GPT-3 这类产品的大模型领域,中国公司和高校依旧缺席。这类产品需要长期而巨大的资金投入(想象一下几万张英伟达 GPU 工作的场景)以及坚定的长期战略,这与中国互联网公司的风格并不一致,而高校同样在资金、数据方面缺乏有力的支持,商业变现的未知性也进一步限制了高校的大模型研究。
|